BrightHub: BrightWind’s wind resource data hub
Welcome to part 1 of our 5-part series on BrightHub, BrightWind’s centralised wind resource data platform. This article series will focus on some of the software engineering challenges we faced when building BrightHub, where a lot of the lessons learnt are applicable to wind analysts and software engineers wishing to do something similar.
This article will serve as an introduction to BrightWind and explain why we needed a centralised data hub. The second article will focus on a relational database schema that handles the more challenging aspects of met mast sensor metadata. The third article will explain BrightHub’s idempotent data file ingestion system that allows us to process files in any order. The fourth article will explain how we use S3 as opposed to a time series database to get the speed that we required for our spikey workload on a relatively modest budget. The fifth and final article will detail the benefits of using a serverless architecture for BrightHub’s back end, and how it allowed us to build a fully scalable system with a small development team.
Who are we and what do we do?
At BrightWind we specialise in wind resource assessment, which is the process of estimating a wind farm’s future energy production. To produce an assessment for a given site, a BrightWind analyst uses data measured on-site and correlates this data to long term reference datasets. Very often, our clients will have acquired this on-site data using a met mast, which is a large mast erected on site that has a variety of sensors attached to it. The attached sensors measure wind speed, wind direction, air temperature, air pressure and humidity.

What does the data look like?
The data recorded by each of the sensors on a met mast is collected by a single logger located at the bottom of the mast. These loggers produce daily data files which contain all the data for all of the sensors for a given day. For any given met mast, BrightWind receives anywhere from 200 to 2000 daily data files to use in their analysis. Different logger manufacturers have different logger file formats, but most of them follow a basic tabular structure with a timestamp column denoting when the sensor measurement was made and then separate columns for each of the statistics measured by each sensor.

Most logger manufacturers also include a metadata section in each daily data file, which contains important information about how each of the sensors was programmed into the logger on the met mast.

BrightHub
At BrightWind, we noticed that when starting a new assessment, a large portion of an analyst’s time was spent extracting and aggregating the measurement data and sensor metadata from the daily files. This was especially time-consuming when dealing with met mast data, where sensor metadata was particularly difficult to deal with, as opposed to measurements from LiDAR or SoDAR units, which were much more straightforward. This aggregation process was also very error prone, as small sensor configuration changes can easily be missed when parsing thousands of daily files manually.
As BrightWind started to grow and take on more assessments, it became clear that we needed a centralised platform to extract and store all relevant information from each file for a given site. This would allow our analysts to worry less about mundane data wrangling and more about getting the most accurate assessment possible. Seeing as this online platform would be the hub for all of our data in BrightWind, we aptly named it BrightHub.
We also saw additional benefits to having all of the data we work with in a centralised platform. It would be easier to explore trends across multiple mast sites seeing as all of the measurement data and metadata would be stored in a consistent format. This ease of access to the data would also make it easier for analysts to perform research such as validate reanalysis datasets and find trends in anemometer calibration values for example, which in turn would improve assessment accuracy.
Initial Planning
After some initial planning, we decided on a high-level AWS architecture that would capture our requirements. We would need to build an automated file ingestion system to extract the measurement data and the metadata from each of the files. The extracted measurement data would be loaded into a database and the extracted sensor metadata would be loaded into a relational database. Once a file’s data had been extracted, the file would be stored away in an S3 bucket.
We would also need a UI to allow analysts to add any extra metadata to the relational database, and a REST API to allow analysts to pull each sensor’s measurement data and metadata into a Jupyter Notebook when beginning their analysis.
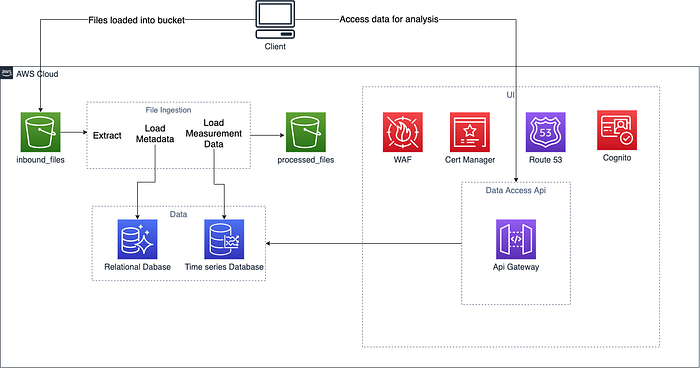
When working through this high-level architecture, we identified 4 areas that needed to be addressed:
- Handling difficult met mast sensor metadata: We needed a relational database schema that would be flexible enough to handle both the difficult met mast sensor metadata and the more straightforward LiDAR and SoDAR metadata
- An idempotent file ingestion system to handle out of order loading: We needed a file ingestion system to extract the relevant configuration data from each daily data file, which would be able to load files in any order and compile their configurations into a useful format for analysts. On top of that, it would need to integrate seamlessly with any metadata that an analyst entered manually, so ensuring idempotency of this system was crucial.
- Fast file ingestion: For a single assessment, an analyst may have to work on data from multiple met masts, each spanning multiple years. Very often we receive all of this data at once from a client at the start of an assessment. Ideally, we would be able to ingest this file dump relatively quickly, so analysts don’t have to wait around to begin their analysis. The data storage method needed to be scalable enough to handle this spikey workload, but also relatively inexpensive so we do not overshoot our modest server budget.
- Simple management by a small development team: With only a handful of developers at our disposal, we needed to ensure that BrightHub would be easy to manage. We needed to make architecture decisions to ensure that things like managing servers and scaling didn’t occupy too much of our time.
Next Steps
Over the development lifecycle of BrightHub, we found that in order to properly address these problems, we needed to make major changes to our initial architecture and database design. The next 4 articles in this series will each cover one of these problems and give an in-depth description into how we solved them. You can read the next article, BrightHub: Handling difficult wind resource data. Check back over the next few weeks to read the rest.
