BrightHub: A simple and cost-effective serverless architecture
by Shweta Joshi
Welcome to part 5 of our series on BrightHub — BrightWind’s wind resource data platform. In the previous article, we discussed our cost and scalability analysis of different databases for storing time series data and the solution we implemented using Amazon S3. In this article, we will be focusing on the serverless components in BrightHub and their advantages as opposed to a non-serverless architecture.
Before we dive further into the details, please check out our previous article Using s3 for spikey time series data ingestion if you haven’t already, to get familiar with the problems associated with processing a spikey time series workload and how we built a serverless architecture.
Kubernetes vs Serverless
Our initial intention when building BrightHub was to deploy and scale the entire platform on AWS using Kubernetes. While there are huge benefits to this container orchestration approach, we saw some problems with it for our use case in particular.
- Cost:
Due to our very spikey workload and relatively low server budget, we wanted to be able to scale to zero as often as possible, thereby minimizing our costs. We didn’t want to be paying for large servers if they weren’t being used. While scaling to zero is possible in Kubernetes (or something similar like AWS Fargate), we would have to endure relatively long cold start times while containers and pods initialize.
2. Developer Onboarding:
Kubernetes provides excellent tools for container orchestration. However, the depth and breadth of the tools it offers means that it can take a long time for a developer to become proficient with it. We wanted something that was relatively easy for a new developer to pick up and start using relatively quickly.
We discussed these concerns with senior consultants at fourTheorem, who specialize in AWS serverless development. They suggested a serverless architecture might be a better approach for our use case. With serverless, we would only pay for what we used, meaning that our platform would automatically scale to zero when it wasn’t in use. Lambda functions on AWS also had minimal cold start times, meaning that we wouldn’t need to wait around for containers to initialize to allow us to pull data or start file ingestion. Also, serverless architectures were relatively straightforward to work with and scale, meaning that onboarding new developers would be a lot easier.
Serverless on AWS
With fourTheorem’s guidance, we transformed BrightHub’s original Kubernetes-based architecture design into a serverless-based architecture. In our previous articles, we have described how we designed the File Ingestion System and our serverless architecture. Following are the major services on AWS that form the backbone of our serverless platform.
Major Components
Amazon S3
Amazon S3 is an object storage service on AWS that can be used to store and retrieve any amount of data. BrightHub uses S3 to store the input raw files and to store the processed and extracted time series measurement data in CSV files. Amazon S3 is highly scalable and allows the platform to process a large amount of data at a very fast speed. It scales efficiently with the amount of data being ingested and reduces the processing time significantly. In addition, it provides notifications when files are created or changed which are used as triggers for our serverless workflows.
AWS Lambda
AWS Lambda is a serverless compute service on AWS that allows you to run your code without provisioning and managing any servers. You just need to upload your code as a ZIP file or a container image, lambda then provisions the server and sets up the runtime environment.
This service is a major component of BrightHub and every small task has been implemented in a Lambda function. BrightHub uses Lambda functions for all the API handlers and for different tasks in the file processing workflow.
Creating lambda functions offers two major advantages:
- It is highly scalable and scales seamlessly to handle a high number of execution requests. For each lambda function there can be as many as 1000 simultaneous executions.
- It can be triggered through other events, for example, in response to an API call, when an object is created in S3 and so on.
Using AWS Lambda, we could split complex services into smaller functions and also create a separation of concerns between different functionalities. Each function can be deployed and tested independent of the other functions providing ease of maintenance and the flexibility to change specific portions of the workflow without affecting the others. It also enables in achieving an event-driven workflow.
AWS Step Functions
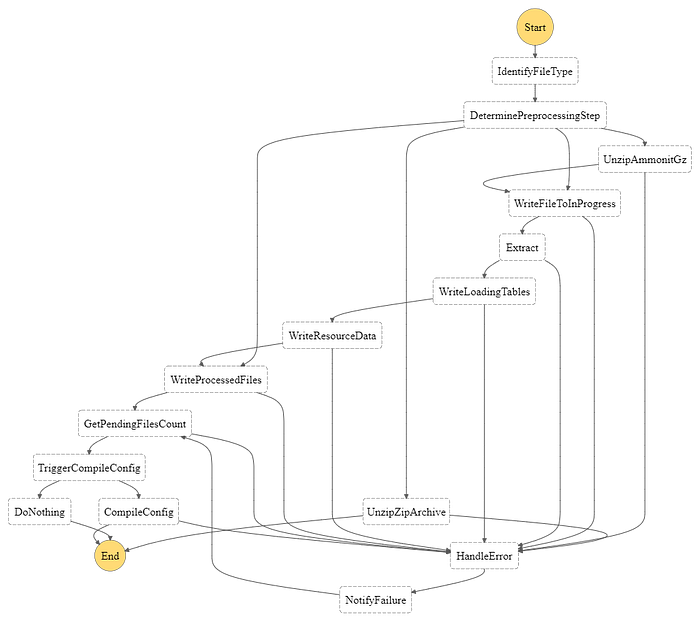
Although Lambda is serverless, orchestration of a large number of Lambda functions can get difficult in a large and complex system. Hence, we explored AWS Step Functions to organize the file ingestion system’s lambda functions into a single Step Function workflow. Each step in the workflow has a well-defined task. The Step Function flow is triggered when a new file arrives in the inbound S3 bucket and the output of each step acts as the input for the next step. A new execution is created for each new file thus enabling the platform to process each file independently. Using Step functions also allowed us to add better error handling, retry and reporting logic in the workflow making the backend more resilient.
Following is the Step Function workflow for the File Ingestion System:
Amazon API Gateway
Amazon API Gateway is a serverless, fully managed service on AWS that makes it easy to create, publish and manage Web APIs. BrightHub extensively uses the API Gateway to expose APIs for accessing the configuration and time series measurement data. All the APIs are backed by Lambda functions written in Python. It also integrates with other services such as IAM to secure the endpoints and authenticate requests to the APIs.
In addition, Amazon API Gateway offers additional features such as request validation. It enables us to validate the incoming requests and ensure that they conform to the data model using json schema, thus, enforcing a consistent request format across all the endpoints. It allows mapping custom error messages and error codes to return more user-friendly error messages.
Advantages of Serverless
Migrating from a non-serverless to a serverless architecture has indeed offered several benefits.
Scalability
Single instances in our previous architecture always formed a performance bottleneck when dealing with many files. Serverless components such as S3, Lambda and API gateway scale automatically to accommodate higher workloads in a fast and fail-safe manner.
Faster processing
As the platform scales to handle a high number of files at a time, we have achieved great improvement in the processing speed. This makes the data available for analysis within a few minutes and allows the analysts to spend more time on their analysis rather than processing the data.
Cost Reduction
Most of the above serverless services charge based on a Pay-as-you-go pricing model. Hence, a cost is only incurred for the usage — such as storage, API calls and running Lambda functions. When there are no files being processed, the cost incurred is minimal. This has allowed us to greatly reduce our operational costs.
No need for Management
Serverless offerings are completely provisioned and managed by AWS. Hence, we did not have to worry about provisioning and managing servers, application deployments and cater to other aspects such as security, backups and monitoring. We used CloudWatch, a monitoring service on AWS for logging and debugging purposes. This reduced our manual effort in management tasks and allowed us to focus more on the development of the platform.
Developing serverless applications
A serverless application has a number of different services and components that interact with each other. Developing and deploying serverless applications can get complex as the number of serverless components increases. Provisioning and managing every single resource can be error prone and time consuming if done manually. As suggested by our consultants at fourTheorem, we use Infrastructure as Code to automate the provisioning of resources on AWS. Developing Infrastructure as Code has offered a number of benefits. The whole infrastructure can be built and configured in a few minutes allowing us to spin up our development environment very quickly. It helps in ensuring a consistent configuration across the development and production environments. This is extremely important, especially for small organizations as there is limited time and availability to debug issues due to misconfigured services. Infrastructure as Code helps in preventing these issues and makes the process of deployment and configuration very simple.
AWS CDK
It is a software development framework for defining Infrastructure as Code through CloudFormation. You can check more details here. You can create a CDK application and define your AWS resources in any familiar programming language.
Serverless Framework
This framework can be used to develop serverless applications on various Cloud platforms. It offers a simple and powerful CLI that lets you handle the lifecycle of your serverless project. You can check the serverless framework documentation for further details.
For BrightHub, we use AWS CDK for components that don’t change often, and Serverless Framework for our microservices that tend to change often.
Next Steps
This was the last part of our series on BrightHub. We hope our experiences and findings will help organizations in addressing similar problems and devising cloud-based solutions. Although this is the end of the series, we hope to write more in the future about developing serverless applications and how we do our local development and testing.
