BrightHub: Using S3 for spiky time series data ingestion
by Shweta Joshi
Welcome to part 4 of our series on BrightHub — BrightWind’s wind resource data platform. In the previous article, we discussed about how the metadata from the daily data files was extracted and how the file ingestion system leveraged the data model. In this article, we will be focusing on the technical aspects of storing the time series measurement data. We will describe our experiments with various databases followed by a detailed explanation of the solution we implemented.
Before we dive further into the technical details, please check out our previous articles on Introduction to Brighthub and the File Ingestion System if you haven’t already to get familiar with the problems associated with extracting time series data and the terminologies used throughout the series.
The Problem
In our previous article, Handling difficult wind resource data , we discussed about how wind resource data can be “difficult” to manage. In a classic Internet of Things (IoT) system, usually the most recent time series data is more important than historical data. With wind resource data measurements however, all the data points are equally important since they need to be correlated with reference datasets. This is what made our requirements of data storage slightly different.
We needed to choose a database that allowed us to write a large number of data points at a time and fetch the entire dataset required for analysis when requested. There can be times during the day when there are as many as 3000 files being ingested simultaneously and at other times the load could fall to 0. A very basic daily data file consists of more than 23,000 time series data points. This number could vary depending on the different types of files and loggers. Hence, we needed a database that scaled up/out within a few seconds as soon as the files are ingested through the ingestion system and then quickly scale down/in when all the data had been stored. Our target was to process 1000 files in under 5 minutes.
Considering our modest budget constraints and the fact that the load could be 0 at times, we wanted a database system that wouldn’t cost us too much when not in use. Hence, we explored multiple serverless/non-serverless database offerings to find the one that satisfied our budget as well as matched the read/write speed and scalability requirements.
Analyzing the Read/Write Speeds and Scalability of Databases
The overall architecture of BrightHub is as follows:

The experiments discussed here focus on the red block of the Time series database above.
To perform the experiments, we tweaked the file ingestion system to use different databases to store the measurement data and analyzed how each database scaled as we ingested more files and calculated the costs of the system.
Following are some speed and cost figures for all the database options that we explored.
DynamoDB — On Demand
DynamoDB is one of the most popular offerings by AWS. It is a NoSQL, fully managed key-value database that can work at any scale and offers millisecond response times. You can check out more details here. DynamoDB was our first choice as it seemed to offer the scalability that we were looking for. Another major advantage is that it is serverless/fully managed, which meant we did not have to worry about managing the database.
DynamoDB quantifies the reads and writes in terms of Read/Write Capacity Units (RCU/WCU). It operates in two modes: On-demand and Provisioned capacity (More details here). The On-demand mode does not require you to provision any capacity upfront and scales according to your workload. We chose the On-demand mode since we were dealing with a spikey workload.
The file ingestion workflow had a lambda function that formed records in the following format and batch inserted them into the database using AWS’s Python library, boto3.

In the On-demand mode, each new table starts with an initial capacity of 2000 WCU. At any point, it can handle a volume double the previous peak. You can read more about How DynamoDB scaling works.
Results
Following are some figures that we observed in our experiment with different numbers of files:
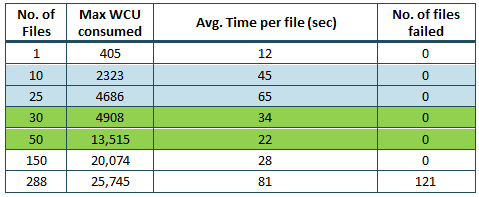
Following is a CloudWatch graph depicting the Write Capacity Units:
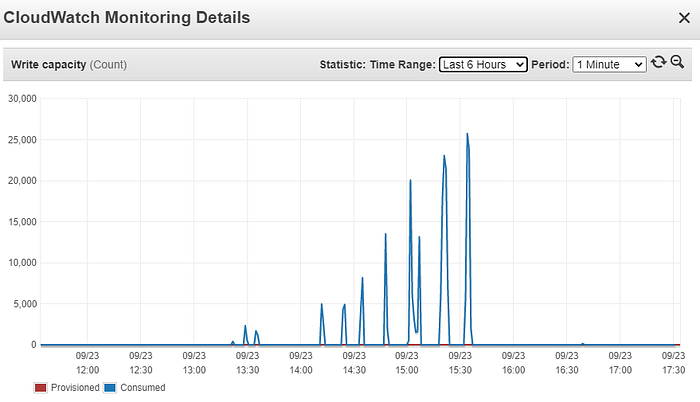
As evident from the numbers above, we can clearly see that DynamoDB can handle almost double the previous traffic. For example, observe the WCU and the time for 10 and 25 files (highlighted in blue). When 25 files were ingested, we hit almost double the value of 2323 WCU. This means DynamoDB had scaled to handle that much workload. A similar trend can be observed in the case of 30 and 50 files (highlighted in green). However, in the case of 288 files, 121 of them were not ingested as the maximum no. of retries in boto3 were exceeded. The failures increased with the number of files. The maximum number of files we could write without any failures was 150 which is far less than what we aimed for. To overcome throttling, we also experimented using a back-off mechanism in the code to avoid errors due to exceeding the maximum retries , but that increased the processing time causing delays.
Although DynamoDB scaled to accommodate more capacity units, it did not scale fast enough to help the ingestion system to process the huge volume of files at a faster speed. Another drawback with this approach was that DynamoDB started with an initial capacity of 2000 WCU. This did not allow it to scale to handle as much as 20,000 WCU when there is a sudden spike in the traffic. AWS recommends spanning the traffic across 30 -minute intervals to allow the database to scale. This was not possible in our case, as we could get 3000 files at once.
DynamoDB — Provisioned with AutoScaling
The On-Demand mode on Dynamo seemed to struggle with our workload, so we decided to explore the Provisioned Mode with the hope that the higher initial capacity would allow it to scale out to handle our higher workloads.
A database table was created with a lower limit of 10,000 WCU and a maximum capacity of 40,000 WCU. We expected this DynamoDB table to be able to handle a workload consuming about 20,000 WCU right away. Following are the figures from our experiment:
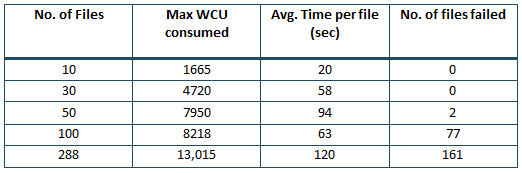
Surprisingly, the results were not very good. It clearly performed poorer than the On-Demand version. To understand this behavior, we tried to analyze the CloudWatch graph below:
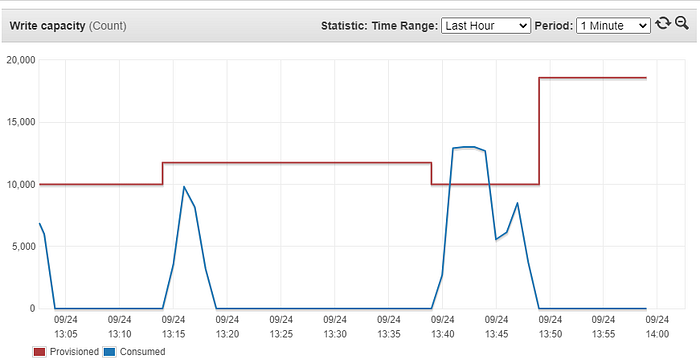
In this case, we have a provisioned capacity of 10,000 write capacity units. As the consumption increased, DynamoDB started scaling, however, by the time it had scaled completely to accommodate the load, all our files were ingested before it could even reach its scaled capacity. This is evident from the provisioned and consumed capacity between the timestamps 13:40 and 13:50. It took a few minutes for DynamoDB to scale out again after the first spike (which is actually very fast but just not sufficient for our workload). We needed a sudden burst of maximum capacity starting from 0 and then within 2- or 3-minutes scale down to 0 again.
Reads
Although, Dynamo DB did not satisfy the write speed requirements, we did a quick experiment to check if DynamoDB offered higher read speeds. Since all the data was going to be pulled through an API, we required the database to fetch the data of about 1000 files in less than 10 seconds. Following are the read times we observed:
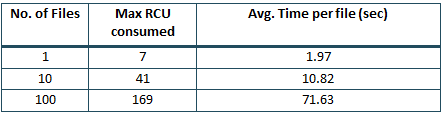
The time taken to read the data from DynamoDB wasn’t satisfactory either.
Cost
Based on our requirement of processing at least 3000 files per day, we did an estimate of the costs we would incur with DynamoDB On-Demand. For about 24000 records in each file, following was the estimate:
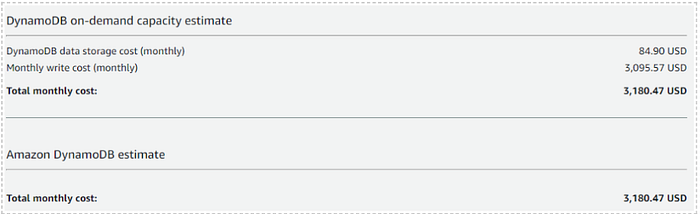
This is the minimum required cost we would have to invest in DynamoDB. However, it was still higher than our budget for databases. Also, the number of files processed per day is not fixed, hence, provisioning any capacity with any certainty was difficult. If we had to provision capacity to allow processing high volumes of files, we would have to provision DynamoDB at a very high capacity, all the time. Considering this, the cost estimate would have been extremely high (as high as USD 33,000 per month). There are workarounds like creating a job to programmatically change the mode to On-demand when not in use, however, this can be done only once per day. Another workaround is programmatically changing the provisioned capacity to a minimum when the workload is zero, however, this would have added an overhead of managing the scaling and would have consumed extra time for changing the capacity.
Cassandra Cluster on EC2
Considering our scalability requirements, the next candidate was using a Cassandra database. Cassandra is a NoSQL, distributed database that offers high scalability and availability (You can check more details here.) We analyzed the time taken for reads and writes on Cassandra clusters of different sizes and different EC2 instance types (You can check more information on EC2 instance types here.) Following are some figures we observed during our experiment. We experimented with a single node to get an idea about the speed and cost.
Writes
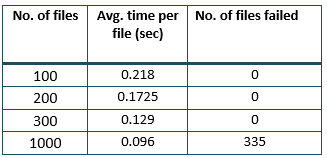
The writes using Cassandra on EC2 were significantly faster than DynamoDB. We tried to improve the performance by adding more nodes to the cluster. Following are the results using 4 t2.large (8 GB RAM, 2 CPUs) EC2 instances for 4 Cassandra nodes.
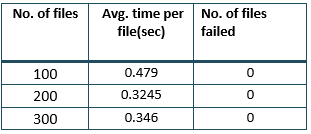
Reads
Following are the read speeds using a single node cluster.
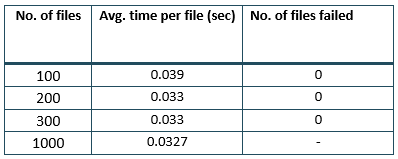
Similar to the writes, reading files from Cassandra was faster than DynamoDB.
Cost
On doing a cost estimate, we found that using an EC2 instance type offering decent performance would cost us about $294 per month. Ideally, a multiple node Cassandra cluster would offer better performance and availability. This would further increase the cost of the database. Since we would be responsible for managing the database cluster, we would incur additional time and resources in these tasks.
The above analysis only led us to the conclusion that although using a Cassandra cluster provided fair read/write speeds for a single node, for better performance multiple nodes would have been required which would not have been feasible in terms of the cost and the effort in managing the cluster.
Amazon Aurora Serverless / Amazon RDS
Relational databases are not a popular choice for storing time series data. However, we did explore this option too. There were multiple issues associated with this approach. One major factor was the cost of using Aurora serverless or Amazon RDS and the complexity in the implementation. Based on our cost estimate and experimentation, using Amazon Aurora serverless or RDS did not seem to be a feasible option.
AWS Timestream
While we were doing our experimentation, a new time series database offering was made available by AWS. We experimented with this database only to find that it could not store data older than a year. We needed to be able to store historical data along with the more recent time series data, hence, AWS Timestream was not suitable for our needs.
Exploring Amazon S3 for storing measurement data
From all the above experiments and as we explored more options, we found that two major factors prevented us from using NoSQL databases — Scalability and Cost. We felt the need to explore a file-based system for storing the data instead of using a database. Being familiar with the capabilities of Amazon S3, we were sure that we could implement a solution at very low costs. However, we needed to perform further experiments to ensure that we got the required read/write speeds for our time series data. Following are some of our observations for the time taken to read/write different number of CSV files.
Writes
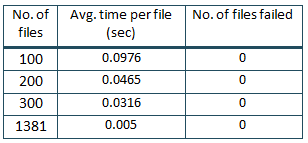
As evident from the numbers above, using Amazon S3, the system was able to write the data quickly without any failures. This allowed us to process (the entire process from reading the raw file from the inbound bucket to extracting the data and writing the files) approx. 1000 files in under 5 to 6 minutes.
Reads
Reading the data for 100 days (roughly 100 files) took approx. 3.67 seconds. Thus, making requests asynchronously through the client, more data can be read in roughly the same amount of time. Amazon S3 scales seamlessly even when the number of reads increase giving similar speeds for a higher workload. Hence, reading 500 files took roughly around 6–7 seconds.
Cost
The cost of the system is significantly lower than what we would have incurred using a database. S3 usage charge for storage is as minimum as $0.023 for 50 TB of data and $0.0004 for GET and SELECT queries (More details: s3 pricing) On running an estimate against the anticipated usage, Amazon S3 would cost us only $8.20 per month which is negligible.
From the above numbers, it was clear that Amazon S3 would give us the required speed and reduce the cost of the system to a great extent. However, seeing as S3 was a file storage system as opposed to a traditional database, we had to ensure that it could be a reliable data store. There were multiple problems that needed to be addressed to implement this solution.
Design Considerations
- File Structure
When we started experimenting with this approach, we followed a file structure similar to the document structure in our DynamoDB experimentation, i.e. the measurement data file would have a timestamp, a hash of the column name and the logger_id, and a numeric value for the data. However, we observed that, using this file structure, the size of the file increased significantly leading to slower reads. A file containing the data from 500 input files had a size of about 810 MB whereas a single individual input file was only a few KB in size. We had to optimize the file structure in order to reduce the file size.
2. Eventual Consistency
In our initial development sprints, we designed the system to use a single large file to store all the data. When a file runs through the ingestion system, the data from this file is extracted, combined with the data in the measurement data file and re-written to the bucket. Amazon S3 is an object-based storage, hence, any update to the file would mean re-writing the entire file. However, this approach had problems associated with it. Consider a case when a file is being processed and at the same time the system gets another file for processing. After the second file was processed, we obviously wanted our single large file to contain data from both the first and second files. However, this may not always be the case due to the eventual consistency model of S3 for overwrite PUTs. This would have resulted in incorrect data leading to problems during the analysis. Hence, we had to ensure that a new object was written each time a file is processed as S3 provides read-after-write consistency for PUTs of new objects.
3. Querying the data
Storing the data in files deprived us of the querying and indexing capabilities that a database offered. We explored Amazon Athena, an interactive query service that allows you to define schemas against the data in the files and query the data using SQL-like queries. We implemented Dynamic ID Partitioning in Athena and analyzed the speed for reads. On experimenting with this approach, we found that Amazon Athena did not improve the speed during file reads.
4. Choice of the file format
Storing the data in the right format was important to improve the read/write speeds. We explored different file format options such as CSV, CSV zipped files, JSON and parquet files (for Athena). While there was not much difference in the read/write speeds using any of these file formats, we had to choose the one that provided reading/writing to pandas DataFrames easier to save the time in conversions. Hence, we chose the CSV file format to store the measurement data.
Implementation of the S3-based Solution
Considering all the above-mentioned problems, we came up with a solution that satisfied our speed requirements and significantly reduced the costs of the system. Following is a high-level diagram of the solution implemented:
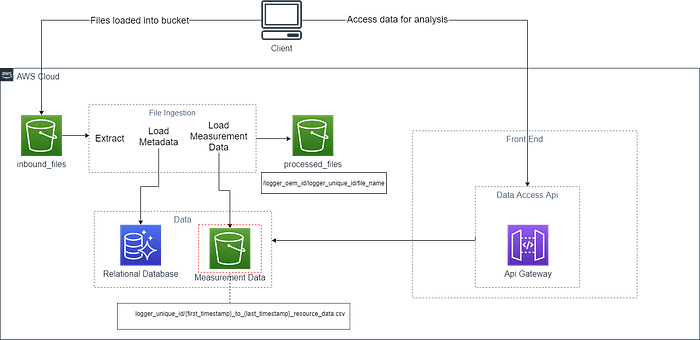
The system now uses an S3 bucket to store the measurement data instead of any time series database. As soon a file is put into the inbound bucket, the file ingestion system is triggered to process the file. The config data and the measurement data are extracted by a lambda function. The config data is written to a relational database and the time series data is put into a file in a separate s3 bucket. In order to ensure that we do not overwrite any other data and maintain consistency, the bucket is structured in the following manner using the data from the file:
measurement-data-bucket /{logger_unique_id}/{first_timestamp}_to_{last_timestamp}.csv
All the files for a particular logger_unique_id are grouped together into a single folder in the bucket. Each file contains timestamps are used to distinguish individual files for every time period thereby creating new objects for each new file.
Reading the data
Due to the limitations and constraints of Amazon Athena, we decided not to use Athena for our queries, which meant reading the whole data and applying the filters in the API handler code. However, by carefully designing the folder structure and by naming the files effectively, performing queries based on timestamps became much easier.
When a user provides a specific time period (date_from and date_to) and the logger_unique_id in the request, the handler can directly scan a specific portion of the measurement data bucket using the logger_unique_id. It first reads all the file names for the logger directly from its folder and based on the date_from and date_to identifies the file names that would contain the data for the requested time period. This reduces the number of files to be read. The relevant files are read into a pandas DataFrame, filtered further to exactly match the timestamps and written to a temporary CSV file. The client is then directed to the location of this query result from where it can be downloaded. In order to avoid exceeding further limits such as lambda timeout or API gateway timeout, we have restricted the API to fetch 100 day’s data at a time. Fetching the data for more than 100 days has been implemented in the client side by making asynchronous queries. Since the architecture is fully serverless, multiple asynchronous queries allow the system to scale efficiently and provide the results at a faster speed.
Summary
In this article, we described the problems in processing wind resource data and the spikey nature of the input to the file ingestion system. In order to facilitate fast reading and writing of the measurement data, we explored multiple time series database offerings. Our experiences with each of the databases, namely, DynamoDB and Cassandra on EC2 have been described in detail.
We saw that the scalability of DynamoDB was not in sync with our sudden spikes in the workload. The cost of this system further deterred us from using it. A single node Cassandra cluster offered moderate speeds, however, to increase the performance, adding multiple nodes would have multiplied the cost. We also described the problems with relational databases on AWS.
A simple approach using Amazon S3 has been described. A careful design along with the knowledge from our experiments on databases helped us in achieving high speed file processing and retrieval of data at very low costs using a fully serverless architecture.
Next Steps
In the next article, we will dive further deep into the architecture and discuss the different serverless components we used in our platform as opposed to the non-serverless components. We will outline the usage of each of these components and their advantages in different areas.
